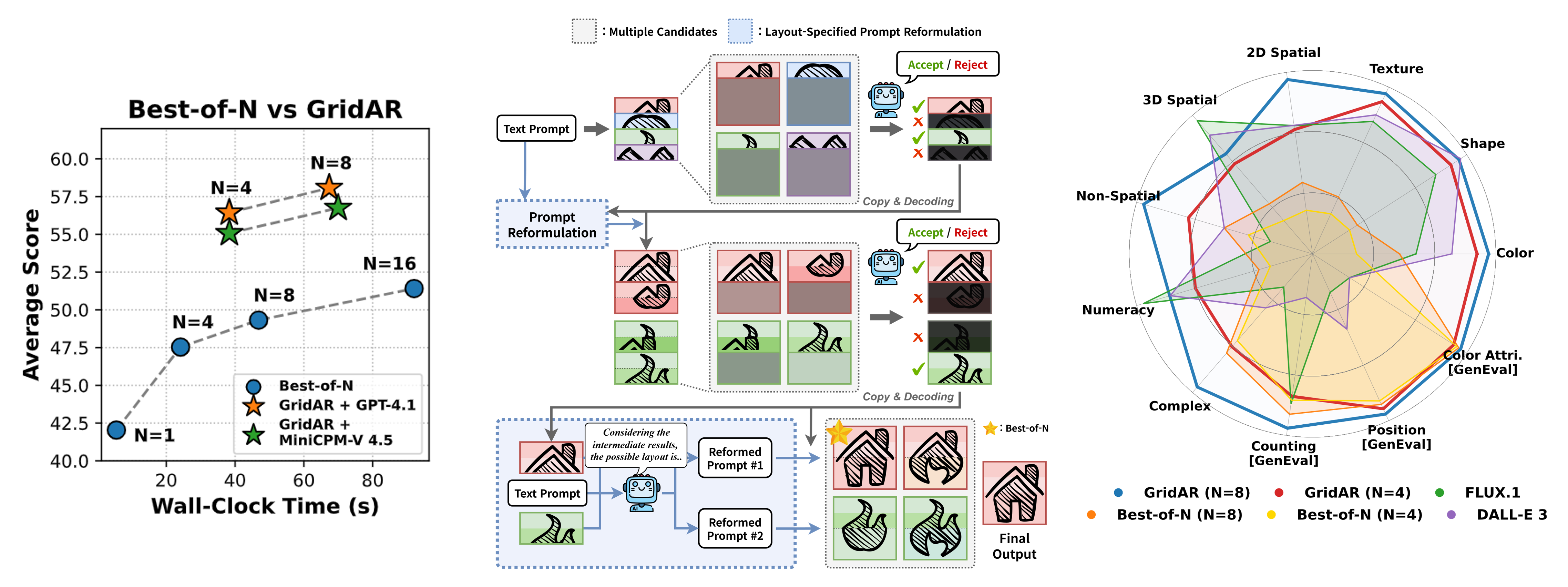
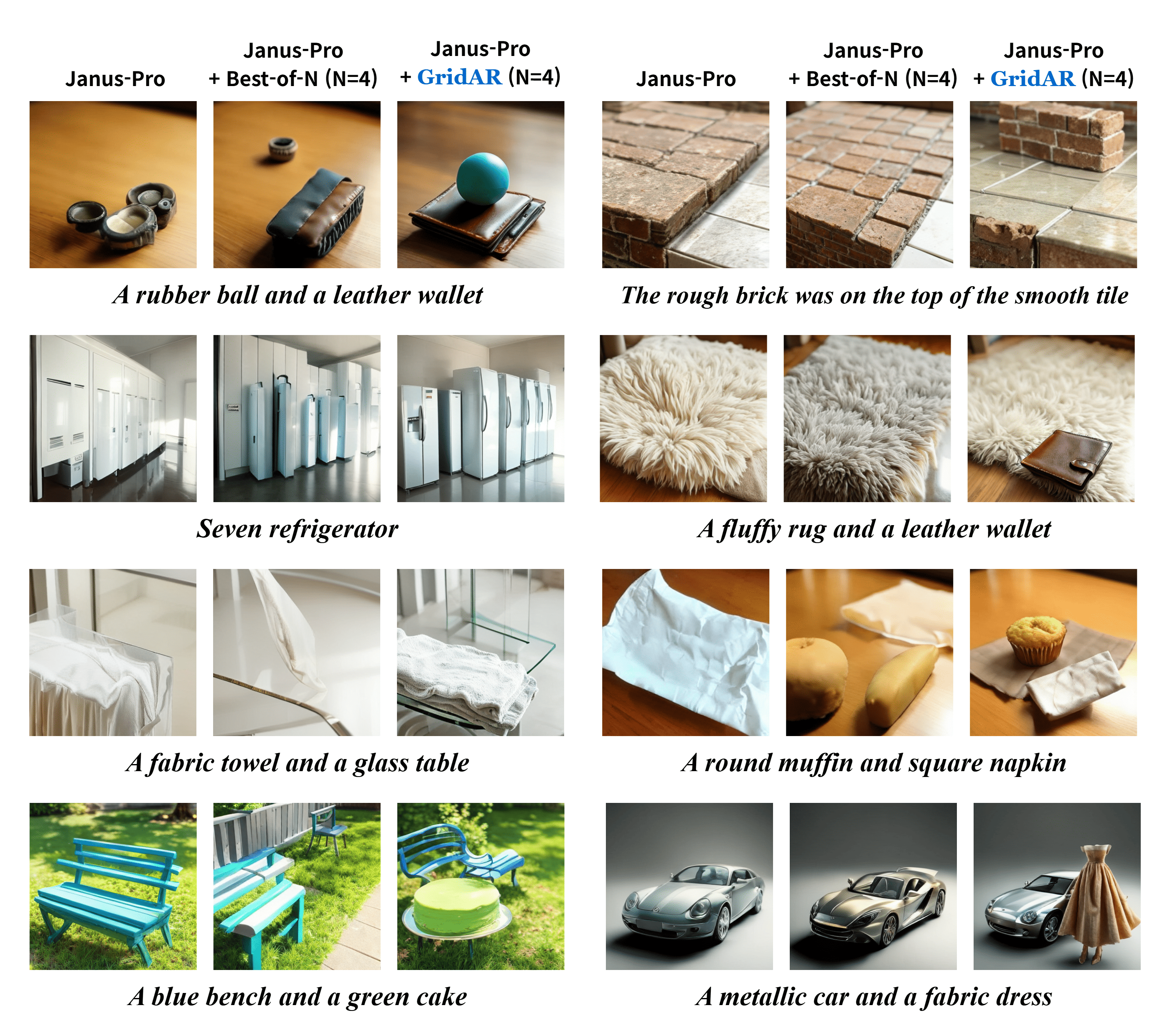
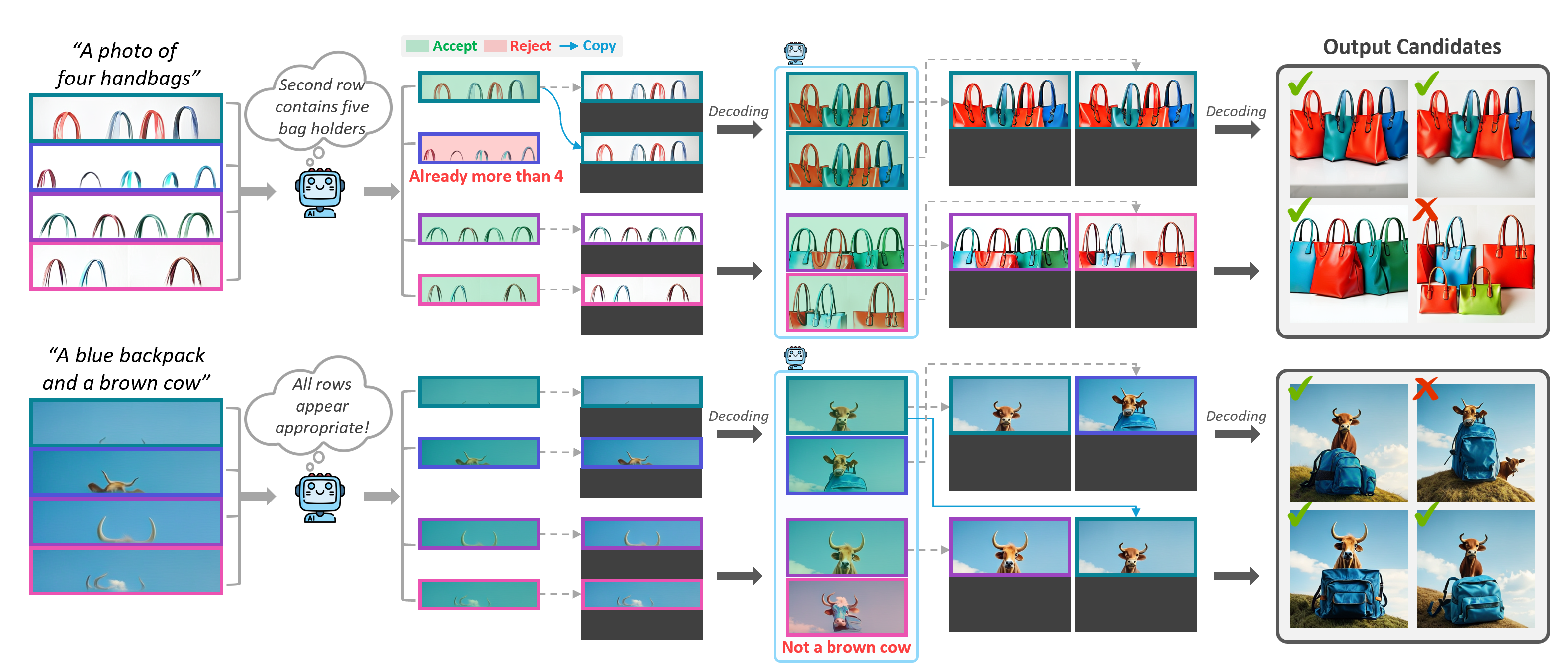
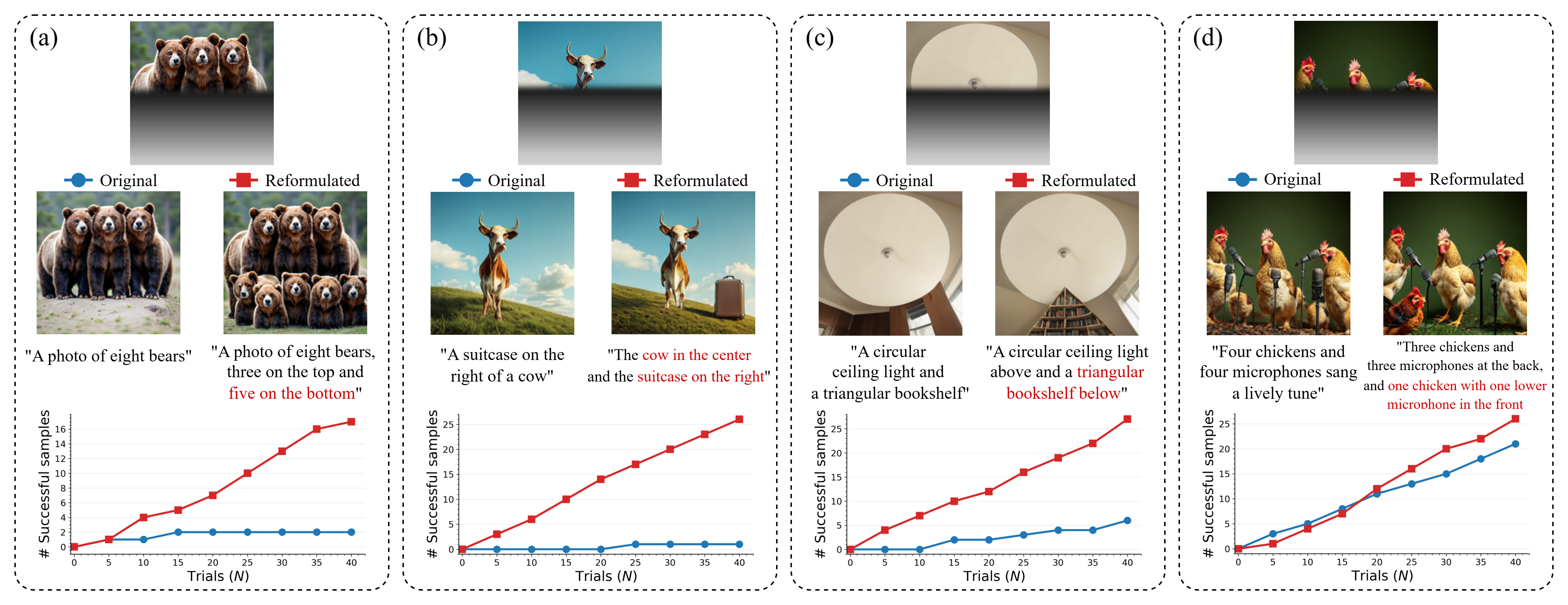
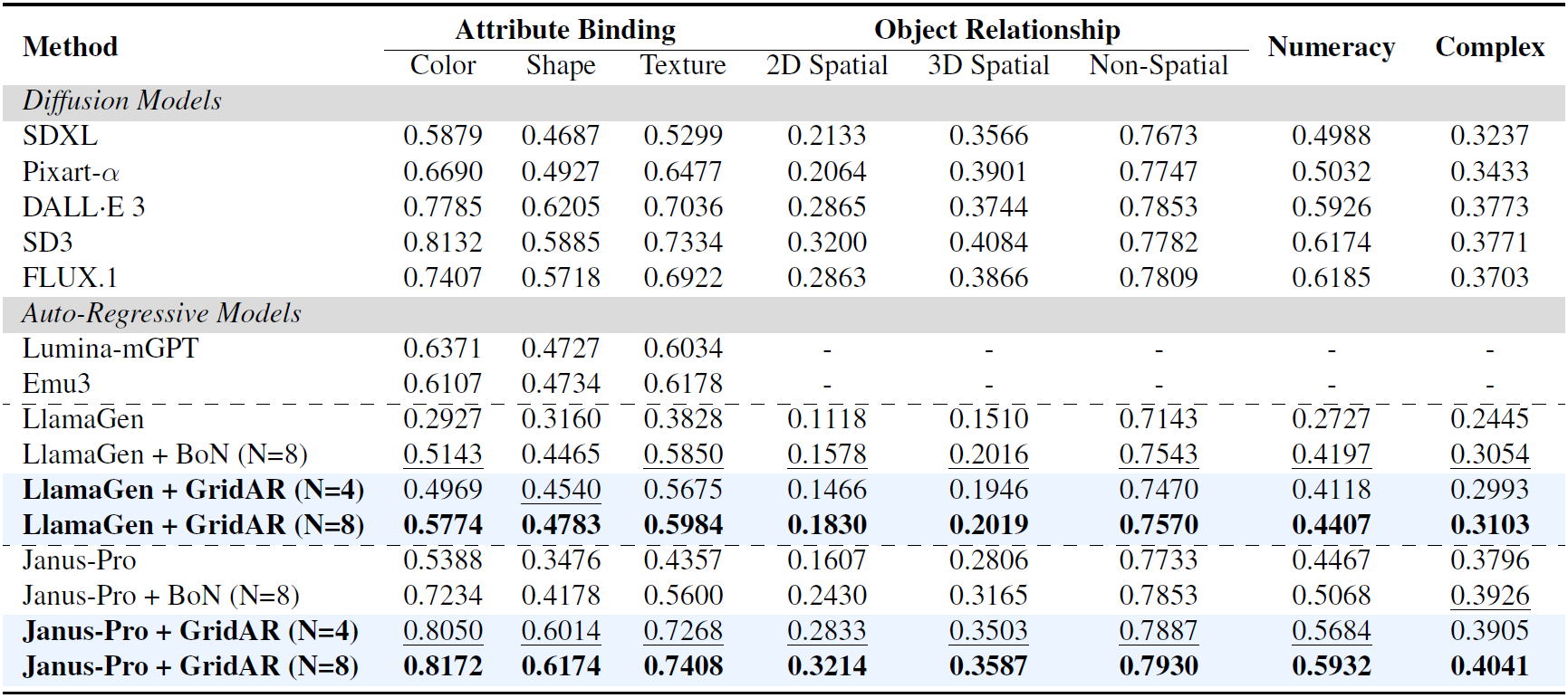
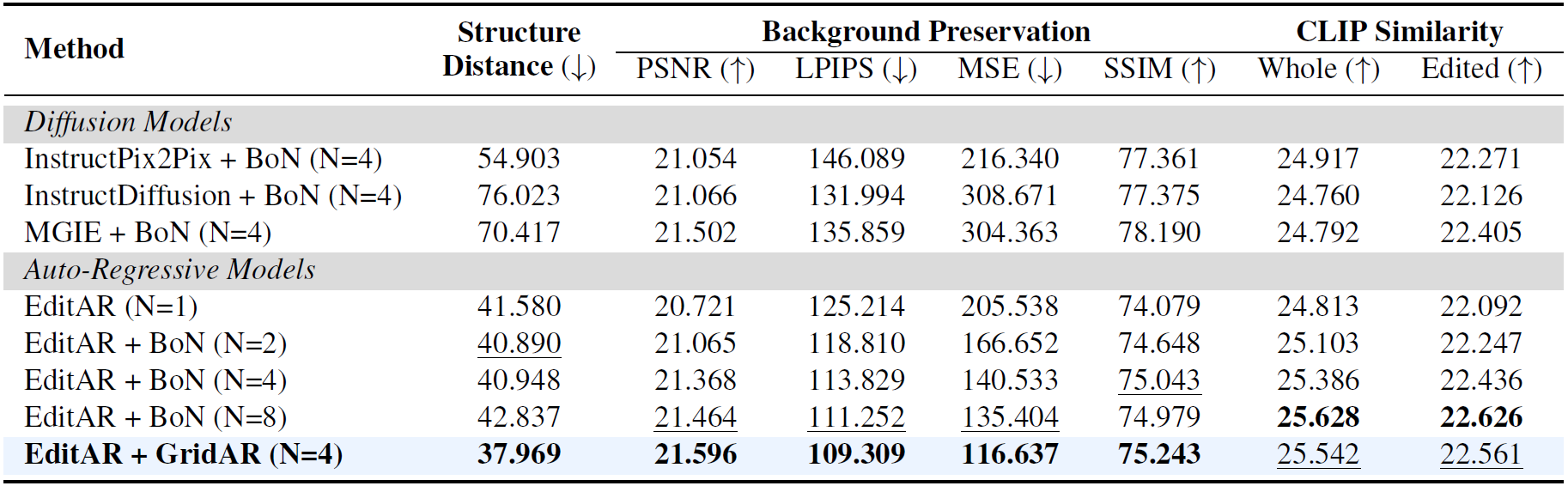
Recent visual autoregressive (AR) models have shown promising capabilities in text-to-image generation, operating in a manner similar to large language models. While test-time computation scaling has brought remarkable success in enabling reasoning-enhanced outputs for challenging natural language tasks, its adaptation to visual AR models remains unexplored and poses unique challenges. Naively applying test-time scaling strategies such as Best-of-N can be suboptimal: they consume full-length computation on erroneous generation trajectories, while the raster-scan decoding scheme lacks a blueprint of the entire canvas, limiting scaling benefits as only a few prompt-aligned candidates are generated. To address these, we introduce GridAR, a test-time scaling framework designed to elicit the best possible results from visual AR models. GridAR employs a grid-partitioned progressive generation scheme in which multiple partial candidates for the same position are generated within a canvas, infeasible ones are pruned early, and viable ones are fixed as anchors to guide subsequent decoding. Coupled with this, we present a layout-specified prompt reformulation strategy that inspects partial views to infer a feasible layout for satisfying the prompt. The reformulated prompt then guides subsequent image generation to mitigate the blueprint deficiency. Together, GridAR achieves higher-quality results under limited test-time scaling: with N=4, it even outperforms Best-of-N (N=8) by 14.4% on T2I-CompBench++ while reducing cost by 25.6%. It also generalizes to autoregressive image editing, showing comparable edit quality and a 13.9% gain in semantic preservation on PIE-Bench over larger-N baselines.